Cache Variables with Global Context in AWS Lambdas
Written by
Carlos Guadir
Last updated on:
October 1, 2025
Written by
Last updated on:
October 1, 2025
As you may know, Lambdas are pieces of code that are executed by a runtime in a cloud provider as a self-managed service that does not require the administration of a server (virtual machine) instance.
To mention some of these cloud services, there are AWS Lambdas, Google Functions and Azure Functions. Commonly, these services have been used to create API’s with the purpose of providing a REST endpoint. There are other use cases like websockets or cron jobs. But for this short article, I’ll talk about REST endpoints.
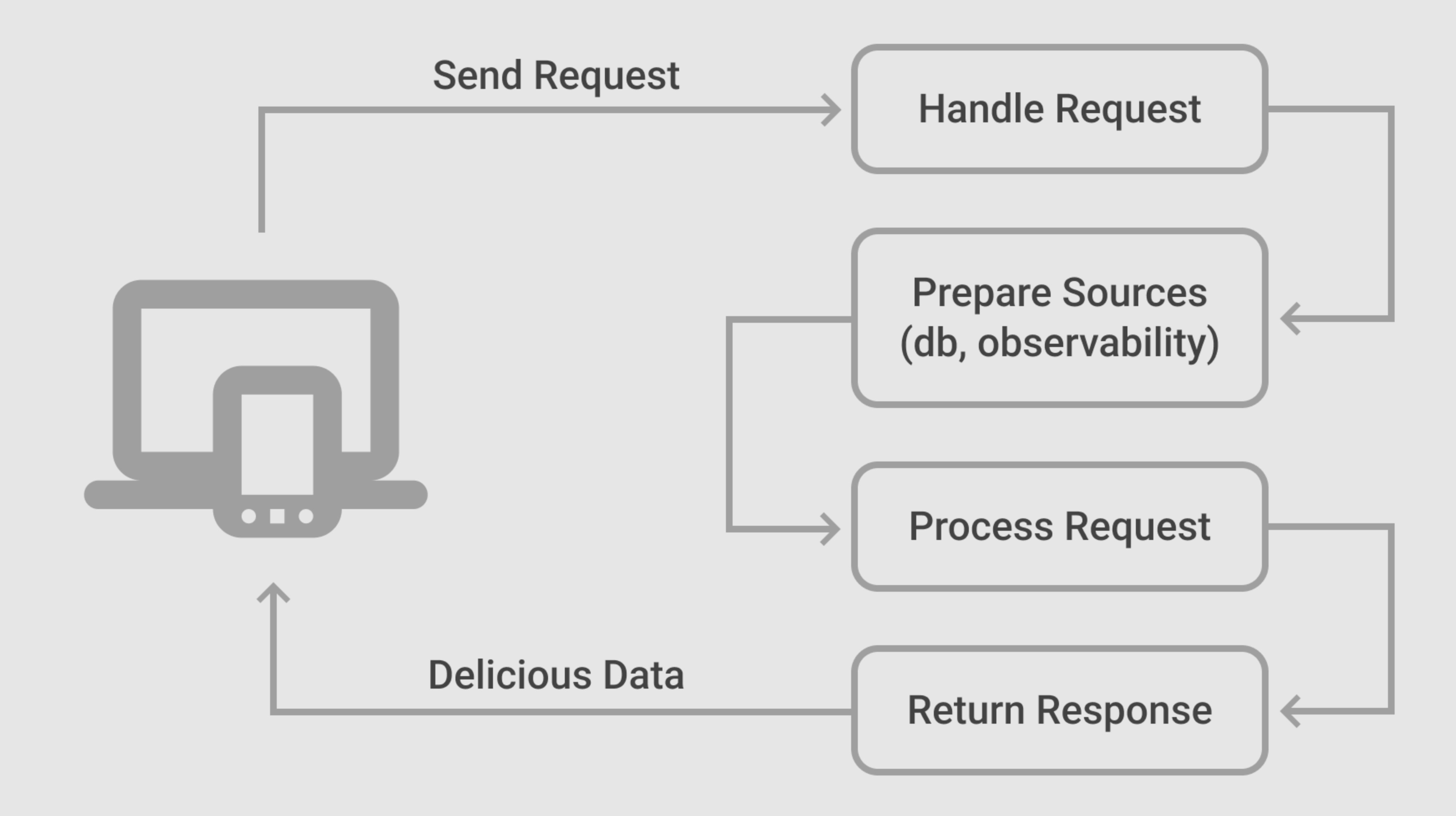
A Lambda function executes procedural code in four steps
Receive (handle) a request from the client. This step is not managed by the code implementation. This includes accepting a specific HTTP request (GET, POST, PUT, DELETE) and receiving headers and data (query params, body, Base64 objects, etc.)
Prepare Lambda. This part handles external or dynamic resources. Some examples here are database connections, resources required by the function like observability services (Datadog, Sentry, Split, etc), and others that the app needs according to a set of requirements. This step is the step the article talks about because loading external resources means opening connections, load configurations, creating instances and whatever lambda needs to work properly.
Process a request. This is the main controller to execute an action with the received request. Here it’s possible to re-use optimizations implemented in the previous step.
Return a response. After executing the actions, the Lambda responds with the relevant data and the status. This is the final step where the lambda finishes the process and returns a result to a client like a mobile device, browser, or IoT device. In patterns like microservices, it's possible to chain other steps with other services.
// 1. Handle or receiving the requestexportconst handler = ( event, context ) => {
// 2. Preparing lambda resources// TODO Await external resources// TODO Await data sources/observability// 3. Processing the requestconst { params } = JSON.parse( event.body )
// 4. Return responsereturn {
statusCode: 200,
headers: {},
body: JSON.stringify({
message: ´Delicious data´,
data: { ...{} }
})
}
}
So, what happens if you have a database connection and observability services on the second step of preparation? If those resources use execution time on every request that affects response time.
Let me tell you about my experience with it. My team had a database connection and a GraphQL server with Apollo Server. So for every request we re-create the database connection and also pre-build an Apollo Serverinstance. We did that to get some flexibility, but the approach doesn’t justify that we forgot an important feature about AWS Lambdas life cycle execution environment. In summary when a request process ends, the runtime anticipates and awaits for a new invocation, caching instances saved in global context to be reused on the next requests. This means that adding a code check for not creating a new instance when it already exists on cache, allows optimization when the function is invoked again.
let connection: Database
const databaseConnection = new Database({
/* Environment variables */})
exportconst handler = ( event, context ) => {
// Heavy stuff like database connection// TODO Optimize this code connection = await databaseConnection.connect()
const { where } = JSON.parse( event.body )
return {
statusCode: 200,
headers: {}, // Don't forget headersbody: JSON.stringify({
message: ´Delicious data from my database´,
data: await connection.findAll( {
where
} )
} )
}
}
We found that Lambdas have a short life cycle before freezing the code execution, so it’s possible to cache some objects in a global context.
The Lambda is alive for some minutes (15–40 minutes.) After that, the Lambda dies if there's no request in the queue. So, you are able to re-use some of the database connections and instances. This speeds up the process for the request almost over 50% for every request in our use case.
Finally, a good proposal for the last Lambdas could be like the next code example. The variable connection is a global variable inside the lambda context. The handler function implements a check if the variable has been previously assigned a connection instance, and only creates a new connection if is not defined. At adding this logic the await on databaseConnection.connect()only affects the first invoke function. The next invocations reuse the connections and optimize the lambda response time.
let connection: Database
const databaseConnection = new Database({
/* Environment variables */})
exportconst handler = ( event, context ) => {
if ( ! connection ) {
connection = await databaseConnection.connect()
}
const { where } = JSON.parse( event.body )
return {
statusCode: 200,
headers: {}, // Don't forget headersbody: JSON.stringify({
message: ´Delicious data from my database´,
data: await connection.findAll( {
where
} )
} )
}
}
Conclusion
Applying this pattern is very close to the singleton pattern. With this, we handle the heavy task for the cold-start in the Lambda function. For the next requests, the heavy process is cached in the runtime memory. So the response time is reduced to a minimum and you are ready for a production release. That’s all, folks. Thank you for reading!
Why is caching variables in AWS Lambdas important?
Caching allows you to reuse heavy resources like database connections, observability services, or prebuilt server instances between Lambda invocations. Without caching, these resources are re-initialized every time, which increases response times and slows down your Lambda function.
How does the AWS Lambda lifecycle enable caching?
After a Lambda finishes processing a request, the execution environment stays alive for several minutes (typically 15–40). During this time, any variables stored in the global scope remain available for reuse. If another request comes in before the Lambda “freezes,” your code can reuse existing instances instead of re-creating them, significantly improving performance.
How much performance improvement can caching provide?
In the example from the blog, reusing a cached database connection improved performance by more than 50% for subsequent Lambda requests. By avoiding repetitive setup tasks like reconnecting to the database or rebuilding services, caching significantly reduces latency.
What’s the best way to implement caching in AWS Lambdas?
Declare connections or resource instances in the global context of your Lambda.
Check if an instance already exists before creating a new one.
Run expensive setup operations, such as establishing a database connection, only on the first invocation.
Reuse the existing connection or instance for all subsequent requests while the environment remains active.
This ensures your Lambda avoids unnecessary work and delivers faster responses.
Is caching in Lambdas similar to the Singleton pattern?
Yes. This caching approach closely resembles the Singleton pattern, where a single instance of a resource is created and reused. In Lambda functions, the execution environment temporarily preserves these instances, which reduces cold-start overhead and optimizes performance for production workloads.
AI is changing software development.
The Engineer's AI-Enabled Development Handbook is your guide to incorporating AI into development processes for smoother, faster, and smarter development.
Enjoyed the article? Get new content delivered to your inbox.
Subscribe below and stay updated with the latest developer guides and industry insights.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
We use cookies to provide our services, to allow us to better understand our audience, and to provide and serve personalized ads or content. By using our website, you consent to the terms of our Privacy Policy and our Cookie Policy, and the use of cookies, pixels, and other technology as described more fully therein
The GPC signal has been honored.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
.svg)