Three models, four real enterprise tasks, five runs each: the findings don't crown a champion so much as map a division of labor.
When a mid-tier model reads like it’s closing the gap on its flagship, every engineering budget in the enterprise perks up. If the cheaper model is “basically as good,” why keep paying for the premium one? The honest answer, it turns out, depends entirely on the job.
We ran three models—Sonnet 5 and two Opus builds—through a benchmark built from real IT work: an access-control merge, an incident correlator, an auditable authorization engine, and a production database migration planner. Five runs each, in sandboxed conditions, scored on whether the work completed correctly and what it cost to get there.
What we found was that there is no single best model. Sonnet 5 owns bounded work on price, Opus 4.8 owns the efficient frontier, and Opus 4.7 owns zero-miss reliability. The cost case for each depends on which jobs you're running and where you're routing them.
Capability: mostly a dead heat, but the higher models pull ahead
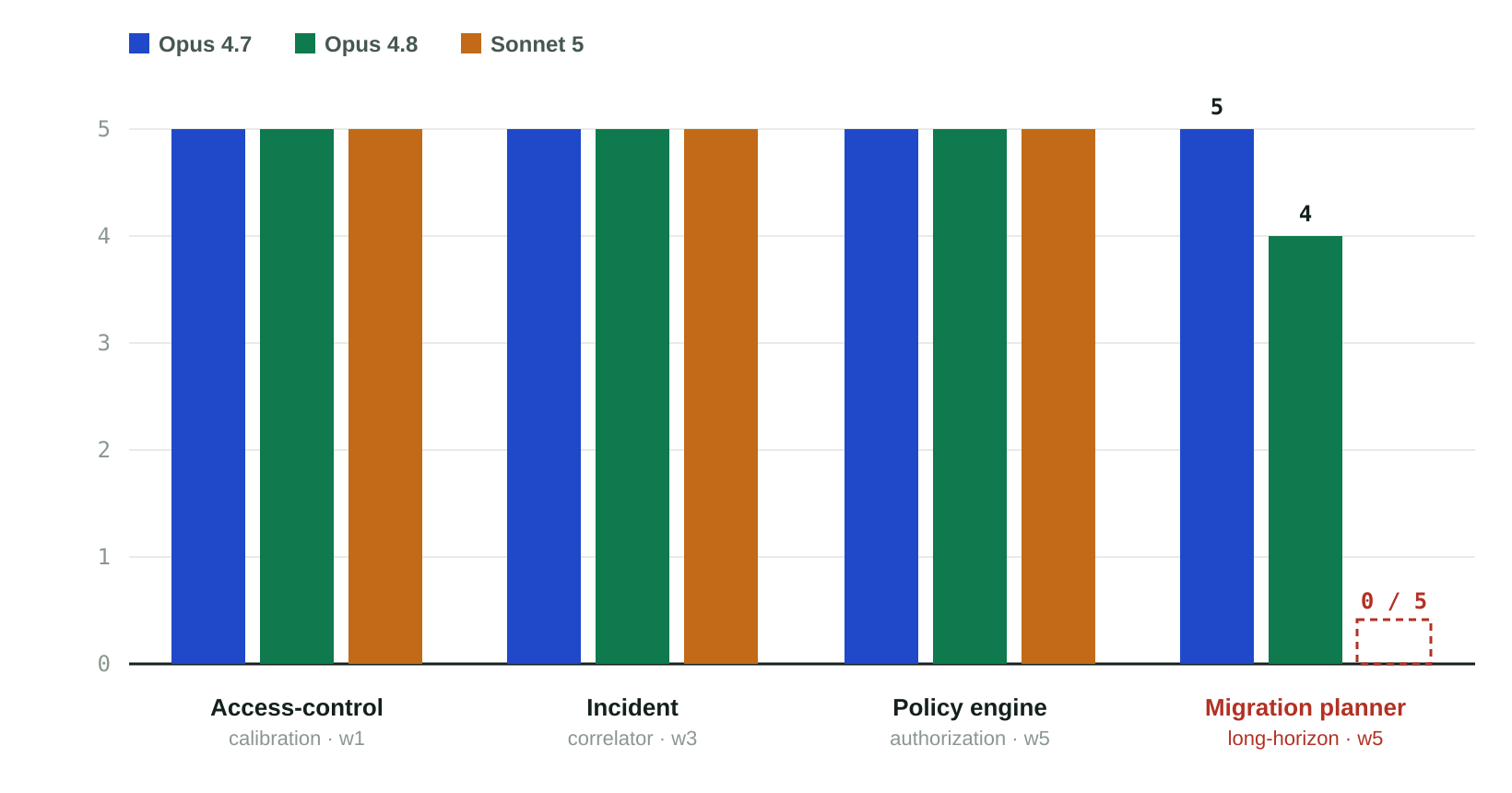
On three of our four tasks, all three models were indistinguishable: a clean five-for-five each. That includes the authorization policy engine, one of our highest-weight, security-sensitive tests, covering deny-precedence logic, role and resource matching, conditional access, and a complete audit trail. Every model got it right on every run. The long-horizon migration planner was the sole differentiator.
Three tasks are a dead heat across all three models. For well-scoped work such as bounded tickets, log and alert triage, and authorization logic, capability is a wash; the decision comes down to cost and efficiency.
Cost and efficiency: two different winners
On the tasks that every model completes, Sonnet 5 is the cheapest route to a correct result, and by a fair margin. On access-control, it costs less than half of Opus. On the frontier authorization engine, a W5 security-sensitive task, it matches Opus per run while still delivering results about 15% cheaper.
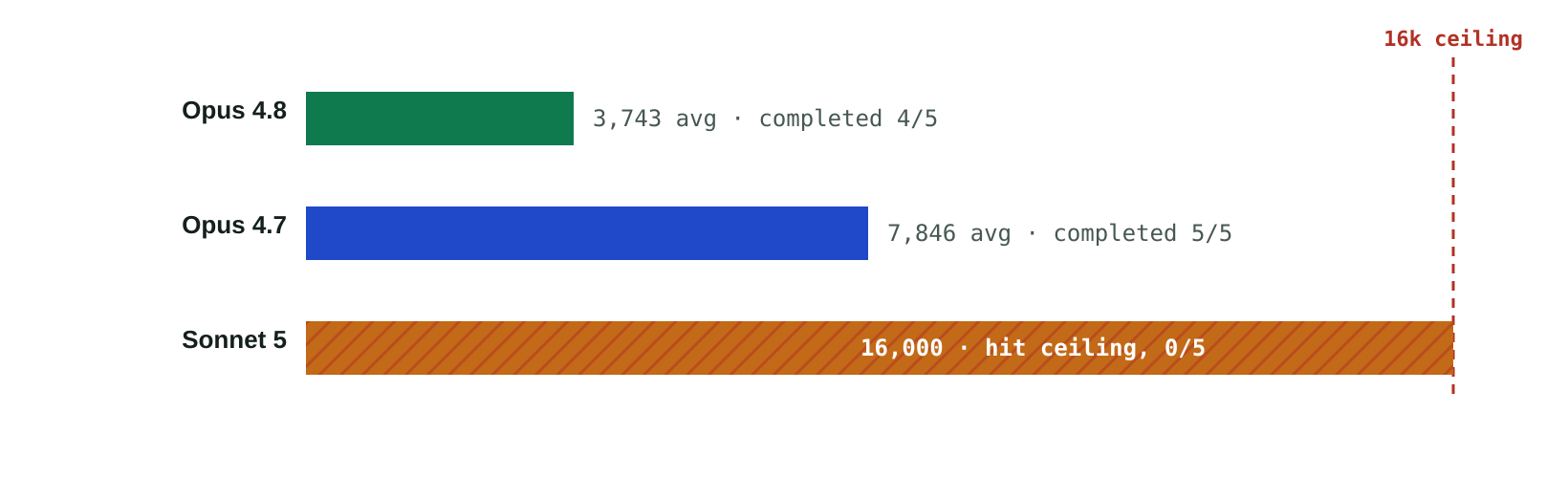
But price per token and efficiency are different things, and this is where Opus 4.8 pulls ahead. It reached the same answers as Opus 4.7 while using far fewer tokens; on the migration task, it used roughly half as many. Compared like-for-like against Opus 4.7, which also completes every task, Opus 4.8 achieves identical results at about one-third lower cost per result. Put simply: Sonnet is the cheapest way to finish bounded work, and Opus 4.8 is the cheapest way to finish everything.
Cost per correct result, each panel scaled to its own task. Sonnet 5 is the cheapest route to a correct answer on all three tasks it completes, including the W5 policy engine. On the migration task, which Sonnet did not complete, Opus 4.8 finishes for roughly 40% less than Opus 4.7.
The migration planner: where models diverge
The migration planner, with its dependency ordering, zero-downtime staging, backfills, foreign-key validation, and rollback guidance, is the long-horizon work that separates capable models from merely competent ones. Both Opus builds completed it. Sonnet 5 did not; it exhausted its output-token budget on all five runs before finishing the plan.
We observed two failures on this task, and both warrant the same caution. Sonnet 5 hit its token ceiling every time, but it’s unclear whether that reflects a real planning limit or simply a budget we set too low for the task. Opus 4.8 completed four of five runs and threw a code error on the fifth. Neither is enough to characterize a model: one run out of five is noise rather than a verdict, and five identical failures may say as much about our harness as about the model. We’ve flagged both, but treat neither as conclusive.
Sonnet 5 spent its full budget without finishing; Opus 4.8 used roughly half the tokens of Opus 4.7 to reach the same result. On long-horizon work, token efficiency determines both completion and headroom before the ceiling.
There’s no single scoreboard here; each model wins a different prize, measured on a different yardstick:
What this means for CIOs
The takeaway here isn’t “buy Opus” or “buy Sonnet.” The data supports a simple rule: match the model to the job.
Default bounded, well-specified work to Sonnet 5. Tickets, incident correlation, authorization decisions, and most day-to-day assistance make up the bulk of enterprise volume. Sonnet matches Opus on correctness here and is the lowest-cost model per result across all tasks. It comes in at less than half the cost on simple work and is roughly 15% cheaper on frontier security work.
Send long-horizon, open-ended work to Opus 4.8. Migrations, multi-step planning, and anything that requires holding substantial state and finishing within a budget all reward efficiency. Opus 4.8 completes this work using far fewer tokens than Opus 4.7, at about a third lower cost per result, while leaving headroom before the budget ceiling. It’s our value lead for frontier work.
Standardizing on one model? Choose Opus 4.8. Teams that can’t run two models need a single build that handles the whole range. As Sonnet can’t yet finish the hardest work, and Opus 4.7 costs more for the same completions, Opus 4.8 is the strongest single bet: near the top on capability, first on efficiency, and lowest cost per completed task among the models that finish the frontier work.
Buy on cost per completed task, not on price per token. The cheapest tokens don’t win if the work never finishes. Compare like-for-like across models that complete the task, then segment by the jobs you run and route accordingly. That’s where a two-model or right-sized-model strategy pays for itself.
FullStack Disclaimer: This is an early evaluation of a brand-new, complex, and multi-layered model. These findings should be treated as directional, not definitive, and are intended to guide real-world teams in running their own evaluations. The engineering team here at Fullstack delivers real-world AI solutions to our clients every day, and tests like these help us build the most effective solution for real problems—which is why we benchmark this ourselves.
Model launches come with headline claims. Our job is to tell enterprise leaders where those claims hold, where they quietly don’t, and which job belongs on which model—so you pay the premium exactly where it pays off and pocket the savings everywhere else.
Learn more
Frequently Asked Questions
Is Sonnet 5 good enough to replace Opus for enterprise work?
For most bounded enterprise tasks—access control, incident triage, authorization logic, and day-to-day assistance—Sonnet 5 matches Opus on correctness and comes in at significantly lower cost per result. Where it falls short is on long-horizon, open-ended work like production migration planning, where it ran out of output-token budget on every run in our testing. For teams running a mix of task types, Sonnet 5 is a strong default for the majority of volume, but it is not yet a full replacement for the frontier Opus builds.
What is the cost difference between Sonnet 5 and Opus on bounded tasks?
On well-scoped work such as access-control tickets and incident correlation, Sonnet 5 costs less than half of Opus per correct result. On a high-weight, security-sensitive task like the authorization policy engine, it still comes in roughly 15% cheaper than Opus while matching it on correctness across all five runs. The gap narrows on complex work but does not disappear on any task Sonnet 5 completes.
When should engineering teams choose Opus 4.8 over Opus 4.7?
Opus 4.8 is the stronger choice when token efficiency and cost per completed task matter. In our evaluation, Opus 4.8 completed the long-horizon migration planner using roughly half the tokens of Opus 4.7 and at about one-third lower cost per result on frontier work. For teams that need a single model that handles the full range of enterprise tasks, Opus 4.8 is the better value: it matches Opus 4.7 on reliability while finishing at a meaningfully lower cost.
How should enterprise teams structure an AI model routing strategy?
The approach that holds up in our data is to match the model to the job rather than standardizing on one build for everything. Route bounded, well-specified work—tickets, log triage, authorization decisions, and most day-to-day assistance—to Sonnet 5, where it is the lowest-cost model per correct result. Send long-horizon, open-ended tasks like migrations and multi-step planning to Opus 4.8, where token efficiency determines both completion and headroom. Teams that cannot run two models should default to Opus 4.8 as the strongest single bet across the full task range.
What does "cost per completed task" mean, and why does it matter more than price per token?
Price per token tells you what each unit of output costs, but it does not account for whether the work actually finishes. A cheaper model that exhausts its budget before completing a task produces no usable result, making its effective cost per outcome infinite for that job. Cost per completed task measures what you actually spend to get a correct, finished result, and it is the metric that determines where routing decisions pay off. In our benchmarks, the model with the lowest price per token was not always the cheapest route to a correct answer.
AI is changing software development.
The Engineer's AI-Enabled Development Handbook is your guide to incorporating AI into development processes for smoother, faster, and smarter development.
Enjoyed the article? Get new content delivered to your inbox.
Subscribe below and stay updated with the latest developer guides and industry insights.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
We use cookies to provide our services, to allow us to better understand our audience, and to provide and serve personalized ads or content. By using our website, you consent to the terms of our Privacy Policy and our Cookie Policy, and the use of cookies, pixels, and other technology as described more fully therein
The GPC signal has been honored.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
.svg)